
Model Evaluation Metrics – Machine Learning Fundamental Concepts
Model Evaluation Metrics
Model evaluation is the process of figuring out how well a machine learning model works and what its strengths and weaknesses are by using different evaluation metrics. Since the results are one of the most important parts of any model, we should always look at them after each testing cycle. From our end, the analysis should keep going back and forth until we get results that match the model’s goal.
Here is a list of the metrics that are used to judge machine learning models:
- Confusion matrix
- Logarithmic loss
- Classification accuracy
- Area under a curve
- F1 score
- Mean absolute error
- Mean squared error
NoteThe book and the AI-900 exam don’t go into detail about model evaluation metrics.
Types of Machine Learning
There are two general approaches to machine learning: supervised and unsupervised machine learning as shown in Figure 3-3.
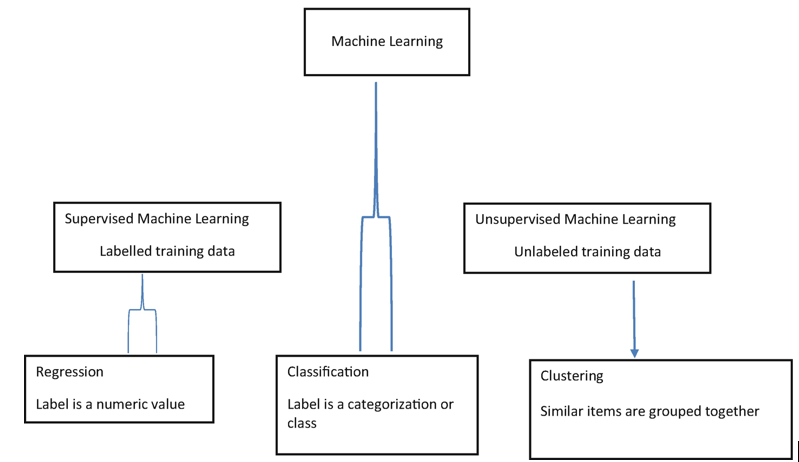
Figure 3-3Types of machine learning
Both supervised and unsupervised machine learning are aimed at modeling an equation that uses available data to make predictions that are as close to the real value as possible.
Both ways need data, but one needs data with labels, and the other needs data without labels.
Supervised Machine Learning
This type of machine learning is defined by its use of labeled data that is used to train algorithms that make further predictions. When it comes to using it, we need some of our data to be labeled, which we can then use on unlabeled data. In other words, the labeled data acts as a teacher for the system to learn from, make the right calls, and produce the right outputs. In this learning, a training set is used to teach models to produce the desired output. This training dataset has inputs and correct outputs, which help the model learn over time. The model also figures out how accurate it is by using the loss function and getting better over time.
Both the input data and the expected output data are given to connect the dots once by making a connection between x and f(x) in the function. This causes our model to learn its function and its nature so that it can make accurate predictions for the future on its own.
The purpose of supervised learning is to train a model of how to classify data by labeling a dataset with relevant information. After the model has been trained, it is checked with test data and then used to make predictions about the output.
NoteLabels are what we want to predict, such as shapes, fruit names, the number of soft drinks sold in the summer, and the number of bike rentals based on weather.
